新博客开张。这篇之前的文章是从我的旧博客处选择性搬迁了一部分到此。
谢谢捧场。
新博客开张。这篇之前的文章是从我的旧博客处选择性搬迁了一部分到此。
谢谢捧场。
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
1 | $ hexo new "My New Post" |
More info: Writing
1 | $ hexo server |
More info: Server
1 | $ hexo generate |
More info: Generating
1 | $ hexo deploy |
More info: Deployment
Do not just seek happiness for yourself. Seek happiness for all. Through kindness. Through mercy.

DEVONthink是很强大的个人数据库软件。我计划写一个系列的帖子来介绍。
由于最近比较忙,所以先按部分来写,逐步发出来。
今天介绍一下用DEVONthink搭建个人web数据服务,类似个人wiki。
当然,更常用的方法是用MediaWiki来搭建个人wiki,同样在Mac下,也很简单。这是题外话,我以后单独写个帖子介绍。
使用DEVONthink搭建个人wiki的好处就在于简单——开箱即用。下载了DEVONthink Office之后,就可以将你的个人数据导入了。
这个软件的好处之一还在于它支持AppleScript,是个深度脚本化的程序,继承了Mac系统下好的软件编写风格。以此,它是个专业级别的软件。如果你懂这种和英语差不多的Apple自带的编程语言,完全可以写一些脚本来配合你特定的工作。当然,DEVONthink自己也带了很多脚本。比如图1中所演示的导入UNIX下man和perldoc两个命令的输出结果的脚本。你完全可以使用这两个脚本将自己常用的命令保存后,方便日后检索。之前也看过帖子介绍如何让Preview来导入man命令的输出结果。显然在DEVONthink中,自带了管理和检索的工具,日后反复使用中要更方便。
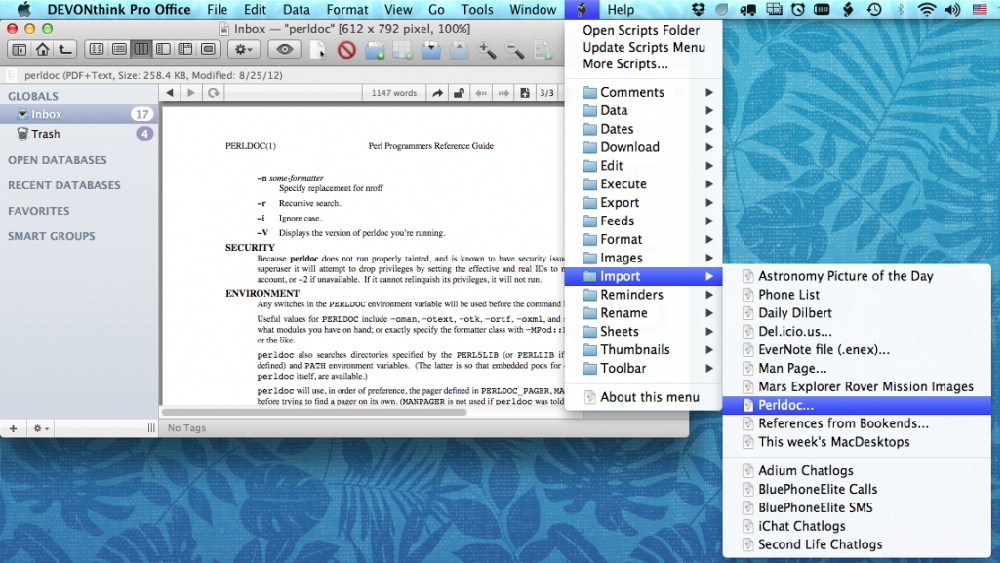
你的数据积累了一些之后,就可以启动DEVONthink的web server服务了。使用[ Command⌘ + , ] 启动Preference…,在server这个选项卡中,键入需要的信息,如Port(使用固定值,方便访问)、用户名、密码等。如果你可以为你的Mac server分配固定的ip,那么就可以随时随地通过外网访问。之后点击启动,这按钮变为stop之后,服务就启动了。可以通过stop按钮后面的任何一个网址来访问。为了方便,你可以将这些网址保存在你笔记本、手机或iPad浏览器的收藏夹中。
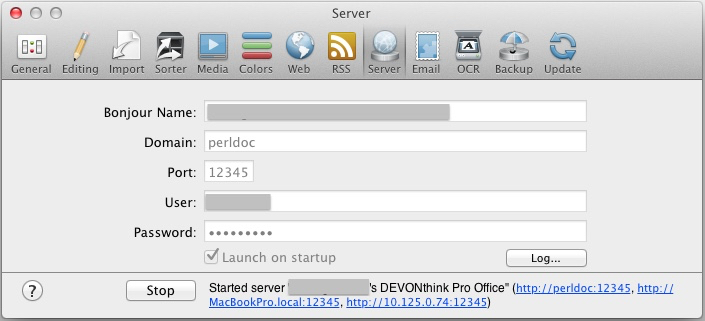
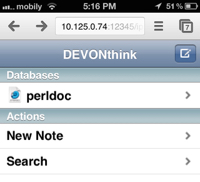
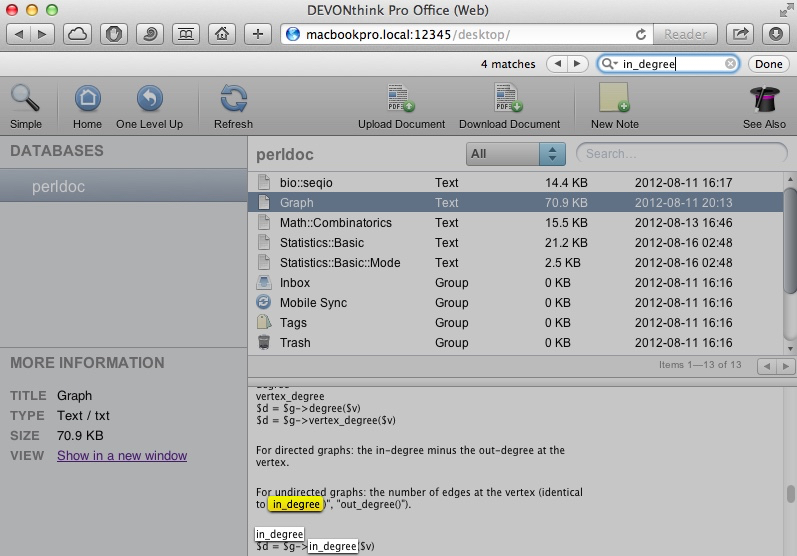
之后,就可以通过其他设备上的浏览器来访问了:在地址栏中输入图2中stop按钮后面你设置的地址,如果设置了用户名和密码,会要求你输入,如图3:
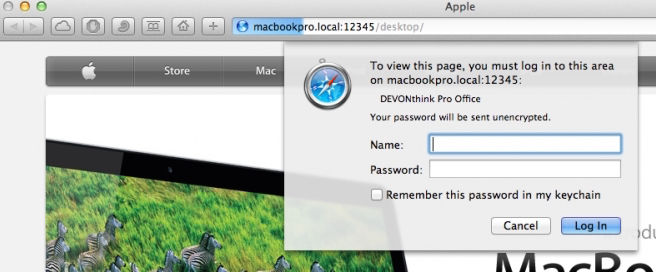
登陆之后,就可以进行常规的浏览,检索,如图4.1,2,3。
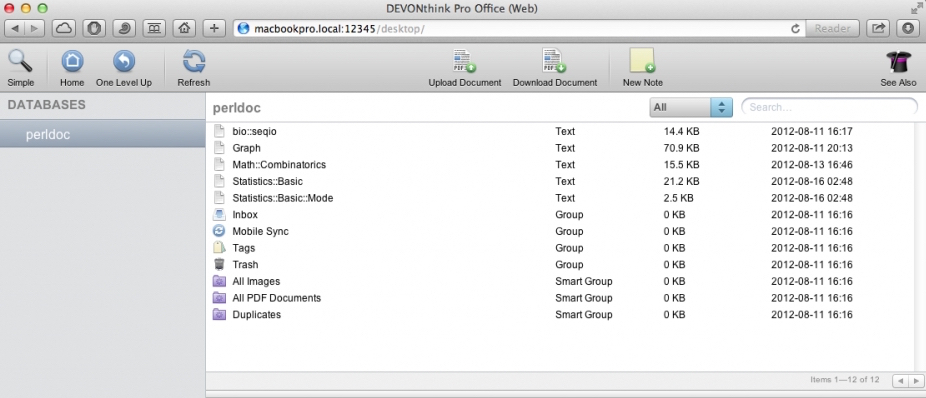
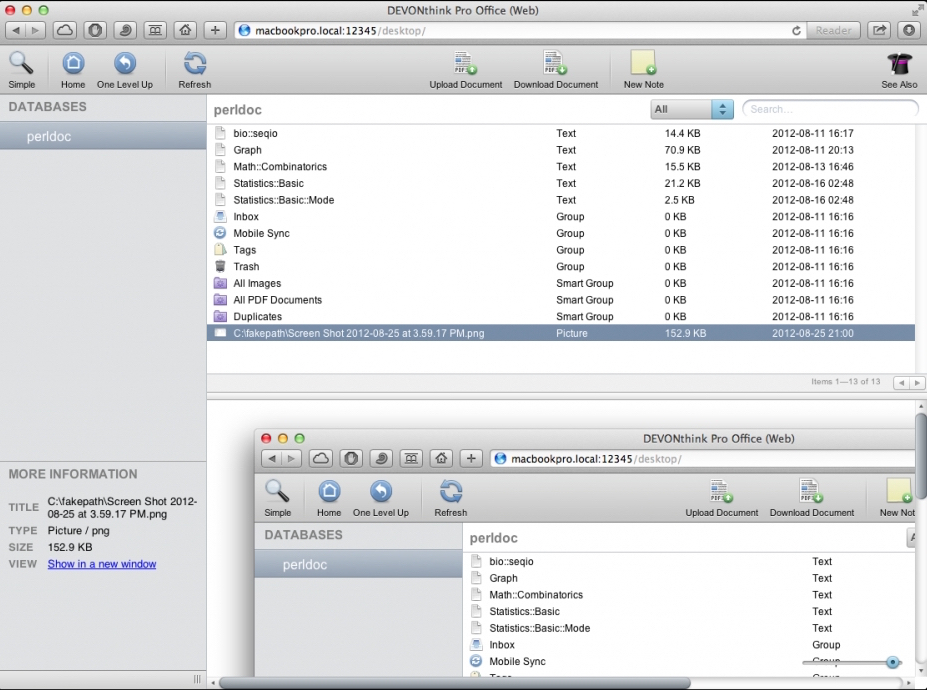
在web浏览模式下,也可以向数据库中添加文件,支持大多数文档、图片甚至音乐、影片的文件格式。
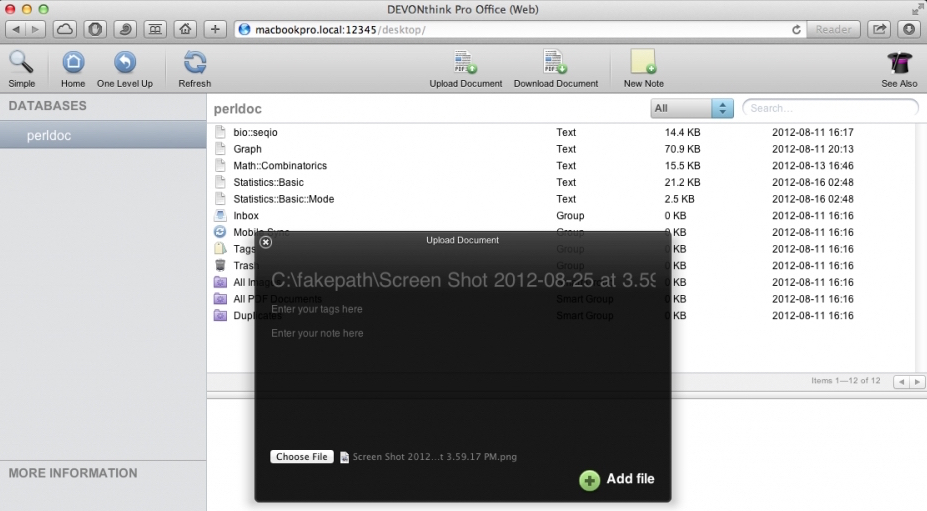
点击图片,在新窗口显示原始尺寸
也可以在数据库中进行搜索。搜索功能其实是DEVONthink作为数据库软件擅长的,不过对中文搜索要用波浪线“~”间隔关键词。

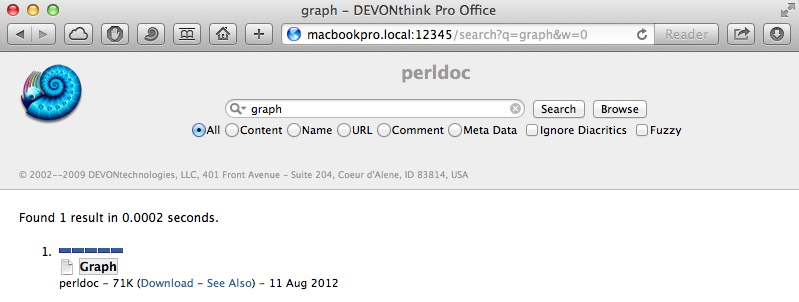
其中比较好的一点是,可以采用浏览器内置的搜索。使用Safari内置的高亮搜索效果,看man和perldoc的结果,实在是一种享受。
下面介绍一个Safari的小技巧。
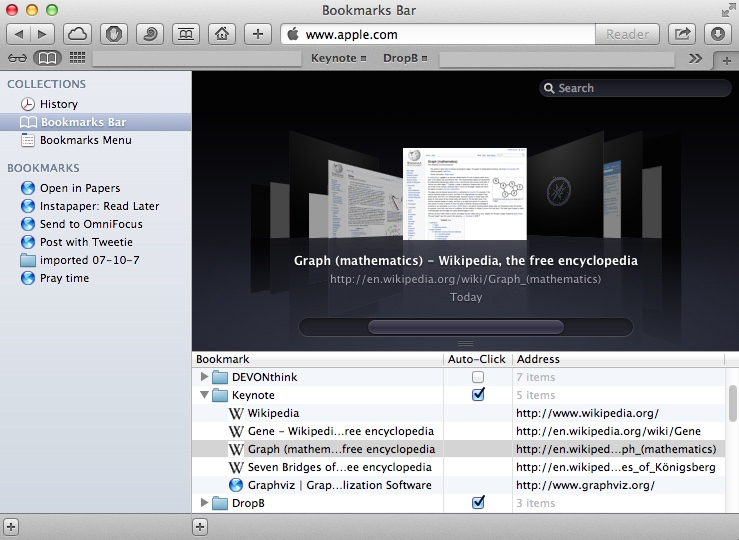
有时候,我们需要一次性打开多个网页,当一个一个点击或输入麻烦又耗时。这时候,可以利用一个Safari文件夹,将需要打开的连接都放进去,如图10,之后选中那个Auto-Click的选项。此时在Bookmark bar中的文件夹图标的右侧会出现一个小方块。这时,点击这个就可以打开里面保存的所有链接。如果想点击其中的单个链接,按住command⌘同时点击即可。
好了。说了这么多,个人wiki的方法先介绍到这里吧。DEVONthink提供一个月的试用期。虽然价格稍贵,但确实是很好用的跟人数据库软件。Enjoy!

Circos 是个画圈图的好工具。在基因组相关文章里展示基因排列,同源性区段,duplication 等,效果很好。由于现在高对平文章对图表的美观程度都有了更高的要求,所以转移到 circos 下来绘制圈图很有必要了(虽然有很多其他的软件和工具)。
Circos 可以安装在 unix based os 上。由于 Mac OS X 是 unix 内核,于是就没有理由不研究一下 circus 的本地化。另外一个原因就是,做生物信息,如果完全把软件问题交给管理员,那么能学的技术问题就很有限。而且走人之后,服务器肯定是不能带走的。因此完全本地化工具包是很有必要的。
circus 的安装其实很简单。下载解压后,cd ../circos-0.55/bin,运行 ./test.modules,就可以看到需要的包有那些已经安装,那些需要手动安装。比如:
1 | ok Carp |
以上是全部安装正常的结果。如果第一次运行这个 check 脚本,显示有未安装的。可以尝试以下两种方法来安装:
由于 cirsos 是个基于 perl+svg 编写的软件,所以大部分要安装的包都可以通过 cpan。
在 os x下,sudo perl -MCPAN -e shel,之后键入 install + 包名称即可,如键入install Math::Bezier。
由于未知原因,GD 无法用 cpan 安装,于是借助 fink。
fink 下移植了大部分的 linux 通用的软件,只是更新会比 osx 稍慢。不过象 GD 这种常用的包更新还很快。bioperl 就没那么幸运了(bioperl 我只能通过 cpan 来安装了,发现比 fink 的速度更快,只是 perldoc 无法调用)。
GD 安装的日志竟然跑了 1 万多行。
由于mac os x的默认路径和一般linux不同,因此要将程序的第一行中“/bin/env”修改为“/usr/bin/env”。
或者使用命令“ sudo ln -s /usr/bin/env /bin/en”建立一个镜像。
现在可以用circos提供的测试文件来检查安装是否成功了。
1 | cd /Applications/Bioinformatics/circos-0.55/example/ |
circos 提供的 tutorials 需要跳转到 tutorials 这个文件夹而不是 data 下运行,这个在官方的手册里是错误的。
搞定。

I am in charge of Date Palm genome annotation recently. In fact, there is only one person doing this, me.
UCSC and Ensembl are the most famous genome sequence databases and both developed effective tool, BLAT from UCSC and pMatch from Ensembl, to do this.
pMatch need input of protein sequence. So it is suitable for use rich datasets to annotate a similar species’ genome without lots of sequence proteins.
BLAT is good at cDNA to genome alignment. So we choose BLAT because we got Newbler assembled cDNA sequence from 454.
The Data Palm Genome sequence assembly based on two data source, the 454 newbler assembled contig and solid mate pair reads.
Newbler assemble the 454 data of genome to contigs which provide the main structure of genome assembly.
Solid mate pair data provide the information of relationship between contigs, including order, gap length, etc.
454 can not provide sequence strand information. After assembly, the cDNA can be sense strand or anti-sense strand. Since both of the genome strand have the ability to encode genes as we defined as positive strand gene and negative strand gene, the BLAT mapping data can provide 4 kinds of mapping results due to the complexity discussed before.
So the first step of annotation is to convert the anti-sense cDNA to sense strand sequence, the the mapping results will remain only two types, the positive strand gene and negative strand gene.
There are several source of the strand information, splice signal, transcriptome data form solid strand specific experiment, CDS prediction data and alignment-based annotation of cDNA.
Splice signal is the first 2 and last two base of intron sequence. cDNA is sequenced from mRNA which only consist exons of gene. When mapped back to genome, the alignment region of cDNA will consist multiple alignment blocks. Blocks of cDNA sequence are usually continuous whereas blocks of genome is separated by unaligned sequence blocks, usually introns.
从题目看就可以归为碎碎念。不过今天不想只写碎碎念~
来Al Khobar旅游比黄金海岸还要简约,连沙滩游都省了,在宾馆睡睡懒觉,看书,游泳。特别是最后一项,再惬意不过了。要知道这可是在消耗石油来净化海水得沙特~
于是,游泳。三天下来快被晒成黑蛋。热带得8月的日头可不是吹的。
于是把大学以来学的所有泳姿都复习了以下。总结体会如下:
自学一项技能无疑是可以的,但会走很多弯路。我从上小学前就开始学习游泳,一直都游不好。直到上初中后偷师学成蛙泳。而学会自由式,波式蛙泳,仰泳还是大学上游泳课之后。按难度排序如下:自学,偷师,上课,拜师。所以在学习新技能的时候,多看看牛人的技术博客会很有帮助的。不过游泳这种很难用语言描述的技能不在此列。
学习技能的过程控制是很重要。其实就是写个监控程序。我不一定了解自己的学习曲线,所以容易在曲线斜率最大的位置放弃。而上课和从师的过程中,会有人对你进行监控,帮助你度过难关。而对过程控制的技能其实也是中学教育,在中国应该是大学教育里重要的环节。很可惜,这点被很多老师忽略了(她们更重视的是知识的传授而不是思维习惯的培养)。相反,很多有自学成功经理的童鞋反倒经验比较多,在进入社会之后的再学习,自我充电的过程中占据优势。
学习任何技能都是循序渐进。蛙泳是入门泳姿,接下来学习仰泳,然后是自由泳,最后是蝶泳。这个顺序是按照对身体素质的要求来的。本人自小体弱多病,于是严格按照这个顺序学习。具体来讲,自由泳和蝶泳对腰部力量和肺活量要求尤其高。在上课的时候,老师也要求自由式的腿部打水要符合要求之后才可以学手部姿势。对应到最近看到的一个分享学习数学的帖子,讲从那里落下,就从那里补:高中的知识忘记了,就从高中的时候补。其实总结为一句话,就是基础很重要,学习不能好高骛远。
心理障碍是我们永远要克服的。游泳的心理障碍就是对水的恐惧。这个很好理解,因为人不是水生的。从羊水里钻出来之后,对这种能造成窒息的液体的控掘就深埋到潜意识里。而结果就是学习游泳时候的身体紧张,时候是动多的不协调,造成问题如疲劳,呛水,不能按照陆上练习的标准完成水下练习等等。在学习新的技能的时候,心理上的障碍是普遍存在的。关于人的两种状态的理论可以很好的和这个题目对应:人存在学习态和舒适态两种状态。在学习态人要不断更新自己的技能和思想,解决不熟悉的问题;而舒适态是不断熟练技能,解决自己熟悉的问题。很显然,后者是人更舒服的状态——我们都喜欢做自己擅长的事情。任务完成的越漂亮,我们越可以标榜自己的聪明。what a shame~强迫自己一直处于学习态,人才可以不断进步。克服你的心理障碍吧。
复习是很重要的。所以这两天好好练习了一下。
把你的技术传授给别人是强迫自己不断学习的好方法。原因不言自明,爱学习,勤奋练习的童鞋无处不在(在此表扬一下万飞童鞋)。比你更有天赋而且勤奋的童鞋(在这里表扬一下胜寒童鞋)无处不在。套用吴清源先生的书名,《天外有天》。把自己的技术高速别人除了激励自己,还可以结交志同道合的朋友。何乐而不为。
以上是今天游泳后的体会。
明天回利雅得,又要努力工作了。加油!
这个脚本可以自动化BLAT的运行。
提供以下功能:
适用:
使用:
经过测试,单个基因组水平(使用人,小鼠,水稻测试)的cDNA注释可以在20分钟内完成。
cpuinfo:
Intel(R) Xeon(R) Processor (Intel64 Harpertown)
===== Processor composition =====
Processors(CPUs) : 8
Packages(sockets) : 2
Cores per package : 4
Threads per core : 1
memory: 16G
写完这个文章后五年,在知乎上看到了这个帖子,对人置于体外的睾丸有了更深入的探讨。自己的知识,多更新才会拥有更多智慧。
原载于基因世界杂志
有句谚语说“人非圣人,孰能无过”。意为大多数人都不是“完美的圣人”。通常,这句话也告诉我们对待自己和他人应该宽容,容许自己有犯错并及时改正错误。在另一方面,每个人应该不断努力走向完美的境界。
而当我们面对生命世界时,我们不得不惊叹自然的完美无暇:从绚烂多彩的珊瑚礁仙境到顶风傲雪哺育幼仔的帝企鹅群;从似万花飞舞的蝴蝶群到海洋里低声吟唱的巨无霸蓝鲸。似乎在地球的每个角落,我们都能找到蓬勃绽放的生命!
面对镜子,我们又会为万物之灵的完美而惊叹。以至有人无法理解这复杂的人体,而写诸如《人体使用手册》之类的“说明书”来。
面对这复杂而完美的生命,就不难理解智能设计论要把它的美丽归功于某个拥有高级智慧的设计师。而对达尔文主义所阐述的:生命从简单形式演化为复杂形式的理论的抵触,恐怕除了人类自封为万物之灵的傲慢,对完美的追求恐怕也是原因之一。
似乎在人的生物本质这个问题上,很多人就无法拿出圣人的心态呢?
我们不妨尝试一次,直面我们为自己的演化而付出的代价。发现美中不足也许能引导我们走向更完美的人生。
人体这个蛋白质构成的躯壳,是历经了几亿年的演化,以单个细胞的蓝本,修修补补,演化至今。上面的不完美之处,仔细搜索能发现很多,比如无用却容易受伤的尾椎骨,男性的乳头,嘴里乱长的智齿等等。
然而每个男人最脆弱的部位不是那传奇的阿喀琉斯之踵,而是悬在两腿之间的睾丸(哺乳动物称为睾丸,在动物界更广泛的称呼是精巢)。担负种族延续重任的生殖腺就这么被放逐到体外。和被颅骨严密保护的大脑相比,睾丸甚至没有较厚肌肉组织的覆盖,这是哪个蹩脚的设计师的作品?
医生对内衣选择的建议能称为这个问题的答案。维持精巢正常的功能要求它必须远离热血循环的身体。相比小概率的外伤,37摄氏度的体温对它功能的破坏性更大。
很显然,恒定的体温在动物的演化史发挥了重要的作用,使得动物具有了更强的适应性和运动能力。
当人的祖先还是海里的一条冷血的鱼时,精巢安全地长在肾脏上方的位置。随着祖先登上陆地,演化出恒定的体温。虽然摆脱了环境温度对生命的限制,温暖的体内环境却变成了扼杀精子的炼狱。
突变给了恒温动物一个机会,让我们的祖先走上了这条岔路,几百万年过去了,精巢被驱赶到了现在的位置。当每个新生开始他最初的旅程时,蝌蚪需要经历如九曲黄河似的旅途,才可以找到出口。
这个放逐的过程,每个男孩在童年都经历过。当男婴出生的时候,睾丸长在它的“祖先位置”,但在几周之后会降落到它之后一生的居所。如果这个过程没有顺利发生,父母们都一定会很着急,尤其在我们这个有重男轻女风俗的国家。
热血对精巢的放逐,这是人体的一处残缺。认识到这个遗憾也没有什么不好——男士们要挑选更合理内衣和裤子。而这则对你们的健康和下一代的健康至关重要。
直立行走是人演化史上的里程碑。下肢独立承担行走的任务;上肢则在演化中形成了更复杂的结构和功能,提供了制造和使用工具的物质基础。
承受了更多重量的结构不止下肢,除了人的椎间盘、横隔膜,还有令很多人痛苦的肛门。
人是唯一会患痔疮的动物。由受压迫的血管所形成的这团组织所带来的痛苦是最剧烈而隐秘的。其形成原因在于:肛门附近的组织所要承受的内脏对肛门血管的压迫,只是在人类直立行走之后才如此剧烈。而现代生活:久坐的工作方式,精细但纤维量减少的饮食,不良嗜好,如对烟、酒、辛辣食物偏好,加剧了这负担的破坏效果。而这负担本来是要由整个胸腔和腹腔的正面来承受的。
最好的预防方法除了做被很多人认为变态的提肛联系,就是回复四组行走。
修长的双腿让人可以站得更高;可以跳出优美得舞步;甚至在田径场上超越人的极限⋯⋯代价就是忍受这难言的痛苦。
认识到痔疮历史,也许读者应该暂停目前的阅读,站起来放松一下。变换一下姿势,能够减轻它的负担。在饮食上多为它着想,能让你的身体更健康,它也会减少烦扰你的次数。毕竟痔疮不是病,疼起来真要命。
也许多少年后,演化的过程会逐渐修复人体的这个缺陷。但医生似乎更擅长修复它。
有学者认为,人的演化速度在变慢。依靠智慧建立起来的人类社会在削弱选择压力。但在生育这个过程里,作用可能不太一样。
母亲的伟大在于十月怀胎的辛苦,也在于一朝分娩的痛苦。在分娩的这一刻,不仅母亲经历了人生最危险的时刻,孩子也穿越了黑暗的幽谷。因为他们拥有了更大的脑容量。
在人的演化历史上,智力的飞跃伴随着脑容量的提升。然而大头娃娃最大的问题是:如何在能顺利通过产道分娩出来。而产道的瓶颈受到狭窄的骨盆的限制。
在分娩的过程中,为了通过狭窄的产道,胎儿的身体发生了不可思议的变化。 虽然,在演化中越来越大的头部是胎儿通过产道的主要障碍,但在分娩前,胎儿的头骨没有癒合,因此具有一定的弹性。胎儿在母亲的屏气用力的过程中,旋转360度,钻过耻骨。
在这个过程中,胎儿的头部会受到产道的挤压。这个过程可能对大脑皮质沟回的形成有重要的作用。
脐带对胎儿的血液供应在分娩开始就停止了。如果胎儿的头部过大,无法按时分娩,因缺氧而致死的风险就很大,同时也给母亲的生命带来威胁。在现代医学尚未发展的时代,生产的致死率很高。而这个事实却没有产褥热和由对它的研究而引发的消毒的普及那样让人熟识。从文艺复兴时期开始流行的紧身胸衣,在其流行的高峰,曾一度成为“妇女杀手”。在胸衣塑形下发育成的狭窄骨盆,让很多准妈妈死于难产。而伊丽莎白可以说是凭借了骨盆博弈和紧身胸衣的协助才登上王位(她的姐姐一尸两命,相当悲惨)。
现代医学引入的剖宫产、产道切开术等让年轻妈妈恐惧的疗法,其实拯救了很多孕育大脑袋宝宝的母亲的生命。
然而,冲突的核心集中在颅骨和骨盆的尺寸。
过大的骨盆会让女性的运动能力受到限制,破坏我们祖先逃避野兽攻击的能力。智力的提升需要更高的脑容量,后代更高的智力意味着选择优势。此时,母亲和孩子的利益虽然存在对立,但命运紧紧连接在一起。
演化到今天的状态是,在尺寸的拔河中,人的发育选择折衷的方案:不闭合的颅骨和没有完全发育的脑可以通过尺寸合适,但不会限制母亲运动能力的骨盆;然而产后,母亲要付出更多的关心和照顾,让大脑没有完全发育的婴儿在保护下完成这灵长类里最长的分娩后发育期(婴儿期)。在这个过程中,孩子需要哺乳,不能行走,没有自我保护的能力。
而为了保证这个发育期的稳定,祖先要定居下来。为了让母亲专门哺育孩子,人需要群居,协作。为了让母亲们在家带孩子,男人们需要外出狩猎。而这一切或许都是为了自己的宝宝“更聪明”。
从祖先的洞穴回到现在。改革开放以来,宝宝们的脑袋似乎一年年在变大。无论是因为国家富裕了,怀孕中母子的营养越来越好,抑或剖宫产帮助宝宝绕过了限制人脑尺寸的瓶颈,失去了选择压力,人的脑容量似乎在向新的高度演化。虽然高的脑容量并不等同于高的智力,但这似乎是人演化的方向之一。即使我们真的回避了产道/骨盆和大脑在尺寸上的博弈,但小腹上的疤痕也不是一个完美的人体应该有的标记。
母亲本也不是圣人。但疤痕正是她们对孩子们的爱所刻下的么?
人不是完美的。在演化学说的理论体系里,最适应环境的物种也不是最具有选择优势的。如果人的演化的方向就是更高的智力,那么这个粉红的大脑袋是否是个“完美”的未来呢?
原载于人人网个人主页
破碎的副歌
副歌 chorus,是歌曲中一句或一段重复的歌词。流行音乐中,一般安排在独唱之后,此时常常加入和声。同时也指合唱歌曲。
——题记
从独唱团发售(2010年7月6日正式发行)到我开始读过了大约一个月。这本装帧像书却实为杂志的小册子,用不小的字体印刷;加上大量的插图和照片,也有好几百页。且不说80后写手韩寒的名号,从一开始高调的征稿到发布噱头似的封面,以及之后数次发布的推迟,似乎掉足了人的胃口。
发售前,我就预定了。网上评论:这本书似乎“承载了很多人”所谓的“希望”。但在所里,这本书似乎从未称为谈论的话题。也许贴上愤青读本标签足以让研究生无视它了。但原因也可能是我们每天在读paper之余,有足够多的帖子可以读。除了自己发现的,还有大量转发的和被朋友推荐的。所涉及的内容五花八门,涵盖养生,投资,考试,励志,两性,等等。当然,读完了,你还得转载和推荐,可不能独吞!
不过,这书似乎卖得不错。刚从武汉考过来的同学在读;毕业来北京找工作的弟弟读了;去在外企工作的姐姐家吃饭,在茶几上我看到一本⋯⋯这是30万册中一些,我还没有无聊到去做调查。
编者说:“作者们提供了非常优秀的文章,但它终究只是一本文艺读本,无论是从程序上还是从本质上,他都无法承载很多人对于改变现状,改善社会的期望。”
的确,它只是本文艺读物,和街边报亭里常见的故事会和读者没有本质的区别。现在你也可以在那里找到它。
平均每篇文章长度不过三页,下班在地铁里的时间够将一篇咀嚼并回味。但压轴之作——韩寒的连载似乎不同。开篇更长的铺陈,对场景细腻的描写,单独成篇又似乎是连续剧第一弹的故事都在表明:长篇小说和其他选文的不同。可以认为这是编者吊读者胃口的把戏,一如明报上连载的《神雕侠侣》;也许是作者对自己想表达什么并没有拿捏到位,在伸脚点点温泉的冷热。但就杂志主体的文章而言,阅读的体验是很轻松的。
不需要记忆晦涩的人名和众多复杂人物之间的关系,不必去记忆库里搜索背景,唤醒那历史知识的碎片。论说文也都够短小精悍,因为作者们想表述的东西不需要更多的文字。而短小精悍的文字也正是我们所需要的。不同的是,现在转载或推荐不是点一个按钮那么简单。
阅读的片段化似乎是一个不可逆转的趋势。
其实何止是阅读。我们已经习惯于在网络上下载歌曲而不是从头到尾听CD。而曲目的顺序似乎也不再重要,第一首常常是主打歌。需要花几个小时聆听和领会亨德尔的《弥赛亚》已成了儿时隐约的旋律。
碎片化的阅读更体现在了隔天发送到手机上的小说片段。每天在地铁里看着至多巴掌大小的屏幕,享受片刻休闲的人们早就习以为常了。
也许怀念那书香的人还存在。但信息时代的潮流不可逆转。
在ipad发布前,apple inc.的CEO Steve Jobs曾放言:阅读已死。在过去的一年里,四分之一的美国人读了不到一本书。字里行间是对亚马逊kindle的微笑的轻视。然而一年后,ipad和ibook store的发布,让这位老嬉皮士之前的狂言再次成为商业运作上成功的烟幕弹。销售的业绩也证明了,综合音乐,网络,电影,阅读,游戏等诸多功能于一体的靓丽终端的确比黑白的电子墨水更有吸引力。
ipad是成功的电子书,但有多少人只用它来读书呢?
在过去的一年里,你读了多少专业书籍呢?小说又读了多少?电影呢?毫无疑问,我们从电影里知道了更多曲折的故事。这些故事更鲜活,角色更有血有肉。如果是3D版本,他们还可以被称为“呼之欲出”。相比书籍,电影似乎让人更容易抓住故事的主线。然而,人也更喜欢缩写和剧透,觉得好了才会去看。回忆过去:每天睡前依依不舍地放下书本,隔天早餐时还在想象或担心主人公的命运的痛苦经历。电影要痛快地多。有谁能计算,有多少没有度过一本罗琳著作的人挤进电影院去观看哈利波特和凤凰社的童话呢?
不记得多少年前,在一个连载的童话里看到主角这样的一句话:书籍是引爆大脑火药库的火柴。如此,似乎更多的工作其实是在读完书本之后。
几年前,那个连载的童话终于写完了。同时搬上银幕的动画版让人失望却可以谅解。短短几个小时的篇幅很难描绘一个少年故事转变为一个成人童话的变化。更不用说那火药库的爆炸了。有足够的火药才会爆炸,这个积累的过程就不是任何碎片化的文字能够胜任的。
厚厚的纸张、密布的文字和之后情节的柳暗花明饱含了作者数年笔耕的心路历程。只有经历过呼啸山庄中如狂野北风一样的爱情和第一主人公洛克伍德在整个故事主体里无故的缺席,读者才能理解艾米莉对爱情的渴望,更重要的是,面对读者,她在对自己的影子不遗余力的掩饰。
而碎片化的生活似乎让我们的没有经历去消化大段的文字了。读者和作者的对话也无法持续太久。如果素材本身就是每天积累下来的零星的生活片段,那么也许作家也没有机会来帮助我们,整合破碎的信息。
时间的流逝让我们逐渐学会享受这些快乐的破碎的片段。正如编者给这卷文字定的基调,每个作者都贡献了他们自己的副歌。尽管作为chorus,这和声略显破碎,但读者们并不在意是否散漫,因为这就是各自独唱的一群。
原载于豆瓣
“瞎忙”一天,到傍晚已是饥肠辘辘。出门觅食,不知到该吃什么。研究所附近屈指可数的餐厅已经被我不知扫荡多少遍,找不到任何能提起我食欲的东西,特别是当我刚刚吃了写反式脂肪制品充饥的时候。
突然想起老妈来的时候请我吃的饭。吃了个菜饱后,被强迫吃了几口的清汤面浮现脑海。讲话:“一顿饭,必须要吃主食”!恩,就这个吧~
要不是被老妈挖出来,这个清汤面还真不好找呢~附近的餐馆无非是打卤面,炸酱面,担担面,“花椒面”,清一色的油乎乎(氢化植物油便宜啊~)的卤;要么就是辣椒,花椒,生怕客人嫌盐酱不够,味道不足,我看大概是卤味道太差,要多放油和盐来掩盖吧~
天色全黑,人不多,一会,清汤面上桌了。面汤表面浮着几点油,绿色的一根是油菜叶子,剩下的就是手擀面条,冒着热气。今年的小麦粉应该还没有上市,虽然是去年的陈面,没有放任何佐料的面条还是泛着淡淡的香气,混合着零星几片葱花的香~哦呀,让我食欲大振~
更妙的是还有家常饼。新出锅外脆里嫩,这面更有咬劲~
回想起小时候,每当新粮食下来的时候,老妈总是会想办法搞到当年的小米,面粉。那热情有点像追星呢~新粮食熬成的小米粥,烙的家常饼,她说那最养人~那个时候从来没有吃出来香,现在大了,倒在这捧着陈面感慨起来了~
那个时候更喜欢的,是秸秆烤的棒子,又脆又香,每年秋天都在姥姥家吃个大花脸,两爪qiao黑,现在想想那抓个烤棒子追着狗跑的日子真是幸福啊~
不知不觉,全下肚了,原来还担心点多了自己消灭不了,看来清淡饮食真是有助食欲啊~让我想起高中晚自习之前老妈给做的面,虽然没有什么特色,但是管饱,加上骨头汤,营养丰富~还是家里的饭实在啊~
清汤面还能找到,烤棒子估计都用管道煤气了吧。哦,不对,在北京烤棒子车不能上街,影响市容。